Will upgrading my CPU make MultiWalk run faster?
Yes, but not as much as you may think.
(Note: also see these related articles Will adding more threads make MultiWalk run faster?, Running large AlgoBB/Fixed Input Parameter projects, and Run Multiple MultiWalk Instances. Running multiple instances may better utilize CPU threads.)
In general, you can compare the raw strength of your current CPU with benchmarks as PassMark. If you can double the PassMark benchmark, then you’ll see a good, significant increase. If the increase is less than 50%, then your gains will be less.
CPU manufacturer’s publish benchmarks statistics so that you can compare the raw power of one CPU against another. However, those bencharmark tests cannot take into account the real-world gains in computational time for any one particular application. So, for example, if the raw power increase is 5x greater than your current CPU and it takes your MultiWalk session 5 hours to run, it would be tempting to assume that the it would only take 1 hour to run that same session with the new CPU.
Unfortunately, life is not that straightforward, especially when we bring other considerations that are not part of the published benchmarking process, such as file read/writes during the MultiWalk session, TradeStation platform limitations (symbol data handling and server requests, thread number limitations) and other elements that will slow the MultiOpt data analysis process down.
If MultiWalk were similar to a pure number crunching application, such as DSP analysis or graphic rendering, then you might be able to compare published benchmarks to your CPU and get a reasonable estimate of the time savings.
But number crunching is just one aspect of MultiWalk and there are other factors involved when considering the benefits of a more powerful CPU.
For those who do not want the nitty-gritty, here is my summary:
Summary: My Take-Away Points
- CPU speed is much more important than number of threads. You will gain an across-the-board performance increase with faster GHz than number of cores/threads.
- Due to TradeStation limitations (and MultiWalk runs under TradeStation), there are no gains beyond 8 cores. Indeed, performance seems to suffer by adding more threads beyond 10-12.
- Simple strategies and simple MultiWalk projects will not see great performance gains with more CPU power. More complex strategies and MultiWalks projects will require and utilitize more CPU power.
- Rather than specifying “Max” in MultiWalk’s CPU threads configuration setting, consider making this equal to the number of CORES in your CPU, not max number of threads. You may get better performance!
For those who want a deeper look into the issue, read on…
The Drag Race: Ferrari vs. the VW Bug
Let’s say you had a drag race between the super fast Ferrari and the humble classic VW Bug. In our race the Ferrari beats the VW Bug by being 5x faster. Now lets say that you put up all sorts of obstacles, such as stop lights and road blocks. Would the Ferrari still win that race? Yes, of course, but it would no longer be 5x faster because of all the stops and starts and slow-downs along the way. In our case, the “obstacles” would be things like starting, loading and stopping a thread for processing or writing analysis results out to disk before moving on to the next computation.
So let’s take a look under the hood of MultiWalk to get more reasonable performance expections from upgrading our CPUs.
Optimization
Factors involved:
- Number of optimization iterations (more iterations = more CPU utilization)
- Size of bars (intraday, small bar sizes = more CPU utilization, daily or large bar sizes, less CPU)
- Strategy complexity and series functions used (more series functions, such as Averager(), ADX(), BollingerBands(), etc., = more CPU utilization)
Each optimized iteration is fired off in its own thread. So the more iterations, the more CPU utilization. If your MultiWalk session has, for example, 10 optimized iterations, then it would only load those 10 of the 24 threads you have available for each symbol/timeframe combo. If that is the case, you will not see a full CPU utilization.
If it is a very simple strategy computationally (such as using lookbacks rather than a lot of series functions, such as Average(), ADX(), etc), then the strategy is not going to make a high end CPU work very hard. It’s going to complete the optimization in a blink of an eye and move on to the next one. Again, you will see low CPU utilization in this situation.
If you are running a MultiWalk session on large or daily bars, then, again, this is going to complete very fast — it’s not going to give your high-end CPU much to chew on. More time will be spent loading the strategy into the thread than it takes to actually run the strategy through all the daily bars defined for the strategy optimization.
However, watch what happens to your CPU utilization on an intraday strategy, such as 15 minute bars compared to the same strategy on daily bars. It is going to take longer to compute the optimization and, consequently, you’ll see your CPU utilization go up while it works to complete the entire iteration in the thread it was assigned.
Here’s a test you can try to see how this actually plays out. I took a very simple strategy that computes six moving averages.
Using Daily bars and 100 optimization iterations for a handful of symbols:

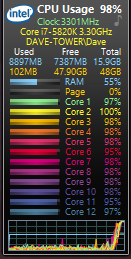
When this article was written in 2021, I was testing using Intel’s i7-5820k CPU. The CPU utilization when MultiWalk is performing optimizations looked like this:

The CPU maintains a pretty constant 30-40% utilization. Any one thread is never at 100% capacity. it’s just too easy and too fast to finish the iteration and doesn’t spend enough time in the thread to max out the CPU.
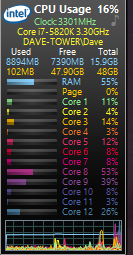
Now, lets try the very same MO strategy and configuration but change it to 15 minute bars:

The CPU maxes out at a constant 98-100% utilization. The computation of the moving averages needs to spend more time in each thread to complete since there are many more bars to process compared to daily bars. The same thing will happen when you enable LIBB (Look Inside Backtest Bars). It presents a much heavier load on the CPU because of the increase in number of bars (data) needed to prorcess.
Walkforward
When MultiWalk is performing Walkforwards, each walkforward in/out computation will be done in its own separate thread. The general process is:
- Load symbol optimization file
- Compute in/out walkforward in each thread, up to max threads allowed
- Wait until all in/out periods defined are done and keep adding more to threads slots as they become available.
- Load next symbol optimization and repeat process on another thread set until all optimization files are processed.
Consider this example on a CPU that can use up to 24 threads. If you are only doing 5 in/out walkforwards on a 24 thread system, then 5 of the 24 threads will be used for each in/out walkforward calculation. This assumes you let MO use the max number of threads for your processor. That means that 19 of those threads will go unused for each walkforward group since you are only analyzing 5 in/out periods in your MulitOpt project.
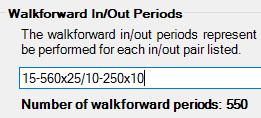
On this system using 5 walkforward in/out periods with net profit fitness function:

CPU utilization: around 16%
Now let’s say you change that to 550 in/out walkforwards using in/out matrix range syntax:
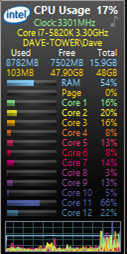
CPU utilization: only 17%!
What happened? My CPU is now using all 24 threads at once, but doing more in/out walkforwards for the walkforward group did not increase CPU utilization. The reason is that the net profit fitness function is too easy to compute for my CPU. By the time it is loaded in the thread, it’s done and loads the next thread!
But, now, let’s give the walkforward something more computationally intensive to chew on using one of the other fitness functions, such as the linear regression formula R^2 * net profit.
Using 5 in/out periods:


It’s a bit more intensive for the CPU at 22%, but we are only loading 5 of the 12 threads available (on my system) for each symbol/timeframe/fitness function.
So let’s now perform 550 in/out walkforwards


CPU utilization: 85% or more!
Since it has 550 in/out periods to compute, it’s going to spend a lot more time maxing out the threads and my CPU utilization went up to 85-90% and maintained that throughout all the walkforwards.
Hopefully this will help in your own CPU upgrade expectations and explain how various optimization/walkforward configurations will present different CPU loads.